
Objetivo
El objetivo de este manual es enseñar a utilizar Git, el sistema de control de versiones más utilizado actualmente.
Git es una herramienta esencial para el desarrollo de software que facilita el trabajo en equipo y la gestión de versiones de código fuente. Permite a los desarrolladores colaborar en proyectos de cualquier tamaño con eficiencia, manteniendo un historial completo y detallado de todas las modificaciones realizadas en el código.
Con Git, los desarrolladores pueden trabajar de manera concurrente en diferentes ramas de desarrollo, lo que les permite experimentar con nuevas características o arreglar errores sin afectar el flujo de trabajo principal del proyecto. Cada rama puede ser fusionada con la línea principal de desarrollo una vez que el trabajo en ella está completo y se ha probado adecuadamente.
Una de las características clave de Git es su modelo de almacenamiento distribuido. A diferencia de los sistemas de control de versiones centralizados, cada copia de trabajo de un repositorio Git es un repositorio completo con todo el historial de cambios. Esto significa que los desarrolladores pueden trabajar de forma local y offline, realizando commits, consultando el historial de cambios y realizando otras operaciones sin necesidad de una conexión de red. La sincronización con otros repositorios, como un repositorio remoto en GitHub o Bitbucket, el cual veremos más tarde, se puede hacer en cualquier momento cuando se disponga de conexión a Internet.
Git también ofrece potentes herramientas para el manejo de cambios y la resolución de conflictos, permitiendo a los usuarios comparar versiones, revertir cambios y fusionar divergencias de manera eficiente. Su sistema de seguimiento de cambios es preciso y flexible, permitiendo a los desarrolladores seleccionar específicamente qué cambios incluir en sus commits.
Este manual tiene como objetivo proporcionar una comprensión básica de Git, cubriendo su instalación, configuración inicial, y las operaciones más comunes utilizadas en el día a día del desarrollo de software.
Instalación de GIT
Linux
Para instalarlo en Linux, simplemente debemos abrir el terminal de nuestra preferencia, y escribir el siguiente comando:
apt install git -y
Una vez ejecutado, podemos comprobar que está instalado con el comando:
git -v
Windows
Para instalarlo en Windows, simplemente iremos al apartado de descargar de la página oficial de Git (https://git-scm.com/download/win).
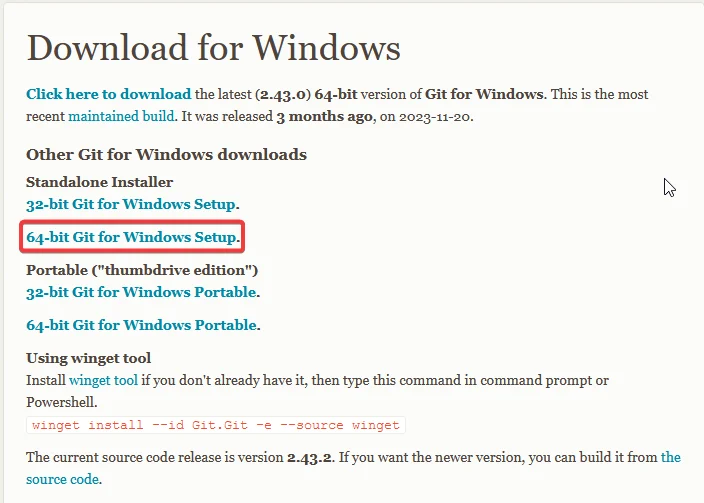
Una vez descarguemos el instalador de preferencia (Standalone 64-bit es el más común, por eso está indicado en la imagen), simplemente debemos abrirlo con doble click, y veremos esto:

Aquí solamente debemos darle a instalar, y procederemos con el proceso de configuración del instalador. Como no vamos a configurar nada específico, solamente daremos siguiente hasta que termine el proceso.
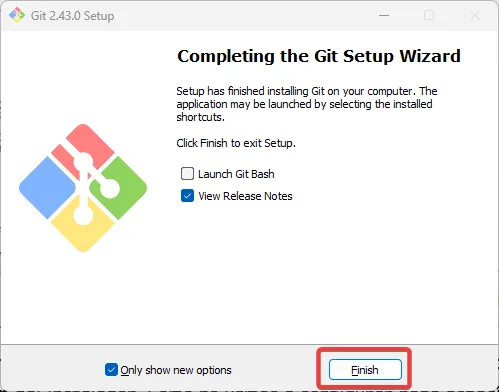
Una vez hayamos llegado aquí, solamente le daremos a “Finish”, y ya tendremos disponible Git tanto de manera gráfica, como en la línea de comandos. Para este manual, utilizaremos la versión de línea de comandos.
Configuración inicial
Antes que nada, Git trabaja con un sistema llamado “branches” o “ramas”. Este sistema lo que nos permite es tener diferentes bifurcaciones de nuestro código, que posteriormente podremos combinar al flujo de trabajo principal.
Por ejemplo, podríamos tener nuestra rama “main”, en la que iría el código fuente principal, el funcional y ultimo que hay. También, podríamos tener nuestra rama “dev” en la que estaríamos trabajando para ir realizando cambios ahí, y una vez queramos que esos cambios se incorporen a la fase de producción, los incorporaríamos en “main”.
Por defecto, Git llama a nuestra rama principal “master”, pero vamos a cambiar el nombre a “main”, ya que es con la que GitHub nombra por defecto a su rama principal, así luego nos ahorramos trabajo.
Para hacer esto, ejecutamos el siguiente comando:
git config --global init.defaultBranch main
Una vez configurado el nombre de la rama principal, vamos a configurar tanto nombre de usuario como correo del usuario. Configurar esto hará que podamos ver después quien ha hecho cada cambio en la rama. Para configurar esto, usaremos los dos siguientes comandos, cambiando nuestros datos:
git config --global user.name "miuser"
git config --global user.mail "miuser@mail.com"
Una vez configurados, podemos comprobar que se han configurado correctamente ejecutando el siguiente comando:

Ahí vemos las 3 configuraciones que acabamos de hacer. Si no realizamos por lo menos la del user.email y user.name no podremos usar Git.
Inicialización del repositorio
El repositorio será ese contendor o carpeta que será la raíz de nuestro proyecto en Git.
Para inicializar un repositorio simplemente debemos crear una carpeta, o en una que ya tengamos, y accedemos a ella.
mkdir manual-git
cd manual-git
Una vez dentro, ejecutaremos el comando “git init”, y si vemos el contenido de la carpeta, veremos que se ha creado una carpeta llamada “.git”
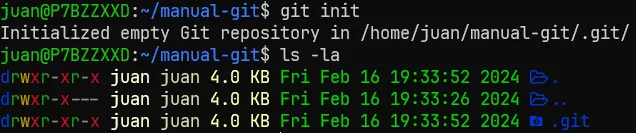
Dentro de esa carpeta “.git”, encontraremos todos los datos del repositorio. Principalmente, no debemos tocar lo que haya dentro, ya que de todos los ficheros los controla Git, aunque en un uso más avanzado, puedes usar hooks, pero eso no se cubre en este manual.
Creación de cuenta en GitHub
Ahora, vamos a crear nuestra cuenta de Github para tener un repositorio remoto. Esto lo que nos permite es tener nuestro repositorio local sincronizado en la nube. Para esto se suele utilizar dos herramientas muy populares: GitHub y GitLab. Ambas plataformas ofrecen servicios de hosting para repositorios Git.
Para este manual, usaremos GitHub.
Lo primero que haremos, será crearnos una cuenta en GitHub desde su página web (https://github.com/signup).
Una vez hayamos creado nuestra cuenta, esta será la página de inicio:

A la izquierda nuestros Top Repositories, en medio una feed de cambios en repositorios de gente a la que sigamos, y a la derecha cambios y recomendaciones.
También podemos ver en la barra de navegación un menú desplegable arriba a la izquierda, y arriba a la derecha nuestro perfil.
Configuración de acceso desde maquina local en GitHub
Antes de conectar nuestro repositorio remoto, necesitamos algún método de “iniciar sesión” en nuestra cuenta, básicamente una manera de poder subir ficheros a nuestro repositorio, ya que, si no nos tuviéramos que autenticar, podríamos modificar el repositorio de cualquier persona.
Para esto iremos al icono de nuestro perfil e iremos a la configuración

Una vez dentro de la configuración, iremos a la pestaña “SSH and GPG keys” en el menú lateral izquierdo

Una vez dentro, debemos darle al botón verde que dice “New SSH Key”, que ahora generaremos.

Ahora, en este menú, podremos ponerle un nombre a nuestra clave, y abajo pegaremos la clave que ahora generaremos.

Vale, una vez aquí, nos quedamos en esta pestaña y vamos a nuestro terminal, ya que tenemos que generar en nuestro equipo un par de claves.
Para esto usaremos el siguiente comando para generar ese par de claves:
ssh-keygen -t rsa -b 4096
Una vez ejecutado el comando, encontraremos ese par de claves en la carpeta de inicio del usuario. Se habrán generado dos claves, la pública (que termina en .pub) y la privada (que no termina en nada).
Pues vamos a leer nuestra clave publica con el comando cat github.pub y ese texto que tiene dentro lo copiamos en el cuadrado que dejamos previamente abierto, y le ponemos un nombre a la clave, como puede ser “PC” o el que queramos.
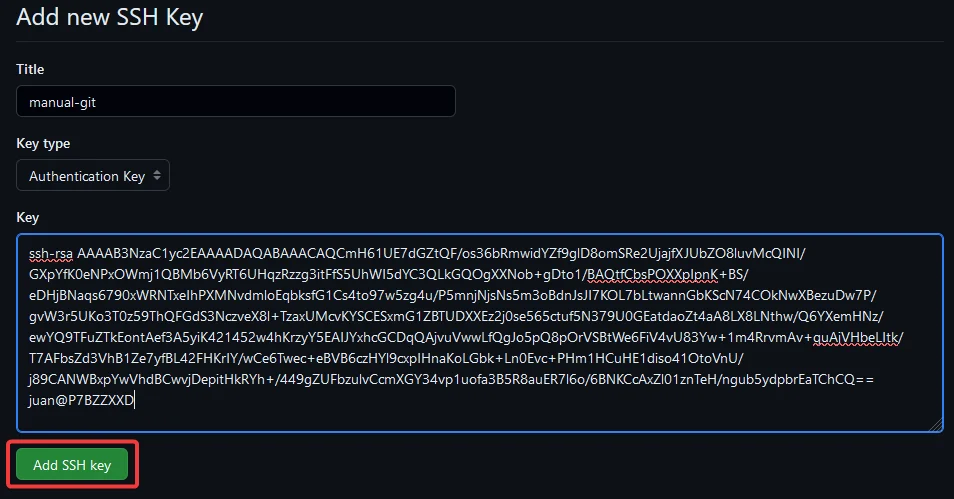
Una vez rellenos los campos, clickamos en “Add SSH key” y veremos que se ha añadido a nuestra lista.
Ya con la clave añadida, tenemos que indicarle a SSH que use esa clave para loguear en Github. Para esto, solamente debemos mover tanto la clave privada como la publica a la carpeta “.ssh” con los siguientes comandos, además de entrar a la carpeta:
mv github .ssh/
mv github.pub .ssh/
cd .ssh/
Aquí es donde se guardan todas las claves de SSH. Para indicarle a SSH cual usar, simplemente debemos crear un fichero llamado “config” e introducir la siguiente información:
Host github.com
IdentityFile github
Ya con esto, tenemos acceso desde nuestra máquina hacia nuestro repositorio de GitHub.
Creación y conexión de un repositorio remoto
Una vez tenemos nuestra cuenta, crearemos un repositorio en nuestra cuenta de GitHub. Para esto, daremos click en el botón “New” que vemos en ambas imágenes.

Una vez le demos click, veremos los datos a rellenar para crear el repositorio.
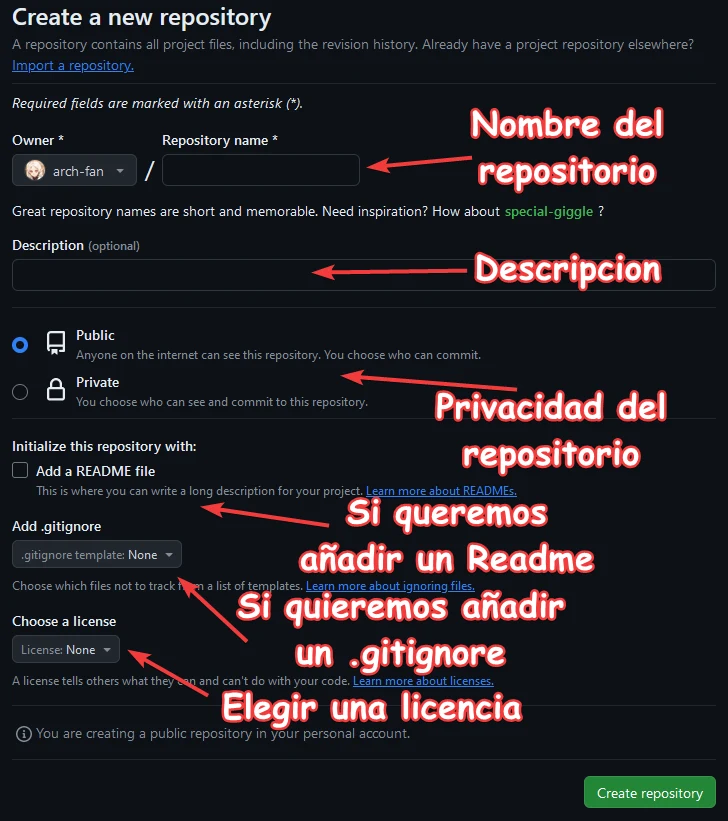
- Nombre del repositorio: En este campo rellenamos con el nombre de nuestro repositorio, en este caso “manual-git”.
- Descripcion: Un breve resumen de nuestro repositorio.
- Privacidad: Si queremos que el repositorio se vea en nuestro perfil de Github.
- Readme: Si marcamos esta opción, se creará un Readme en el repositorio. Este fichero es especial en GitHub, ya que al entrar en la web que genera el repositorio, veremos en grande lo que escribamos. Este fichero se escribe en formato markdown, el cual tiene una sintaxis especial. (Mas información en https://markdown.es/)
- .gitignore: Esta opción nos crea un fichero .gitignore dentro de nuestro repositorio. Este fichero tiene la funcionalidad de indicarle a Git qué ficheros ignorar en el flujo de trabajo. Esto es muy útil por si tenemos ficheros con credenciales, como puede ser nombre y usuario de una base de datos. Estos ficheros son comúnmente llamados “.env”
- Licencia: Esta opción nos permite asignarle una licencia a nuestro repositorio. Estas licencias nos permiten decidir que se puede y que no se puede hacer con nuestro código fuente. (Mas información en https://docs.github.com/es/repositories/managing-your-repositorys-settings-and-features/customizing-your-repository/licensing-a-repository)
Una vez seleccionadas todas las opciones que queramos, clickamos en “Create repository”, y ya tendremos creado nuestro repositorio. Se vera algo asi si no hemos elegido ninguna opción de crear ficheros.
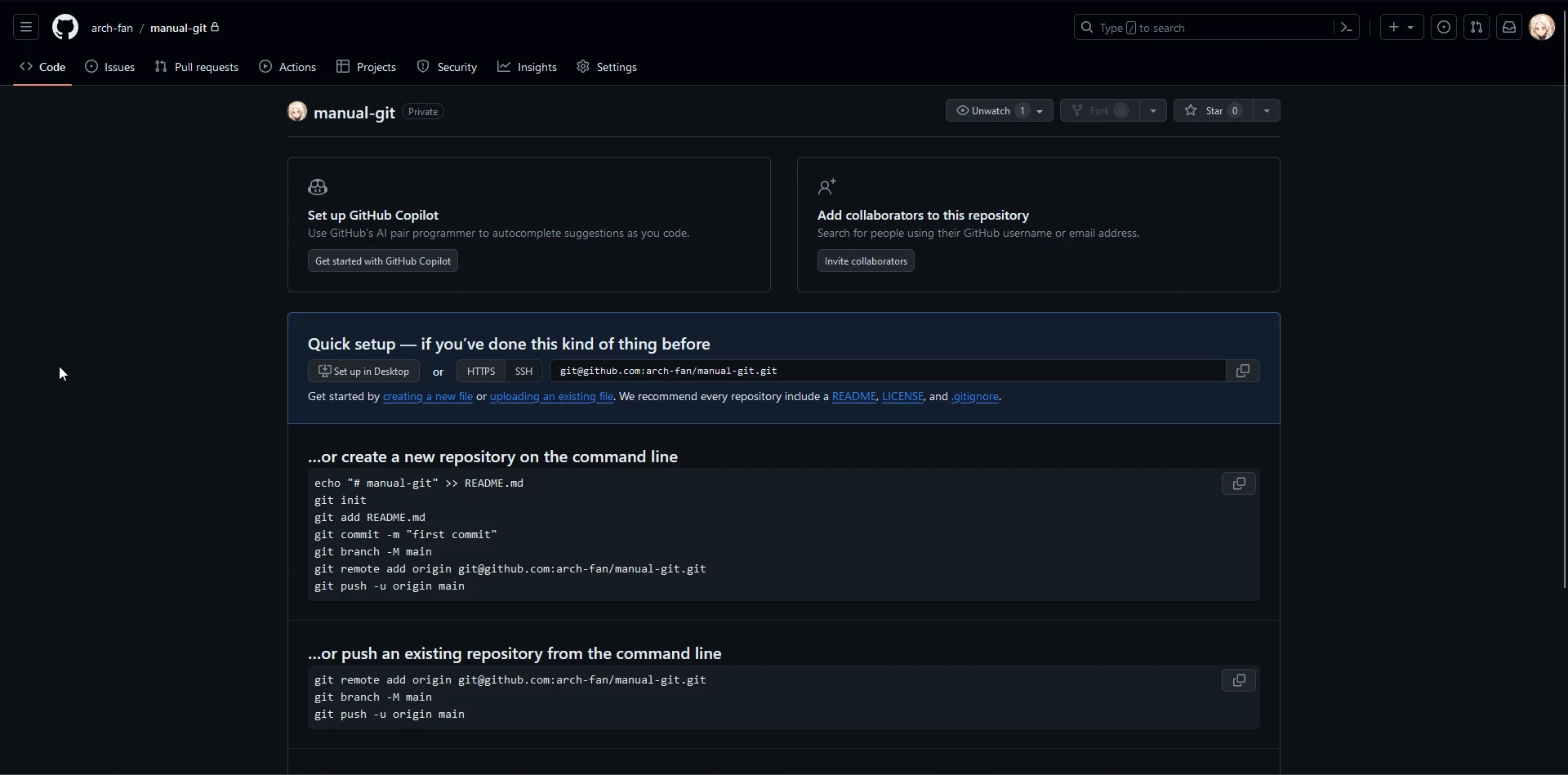
Ya creado, tenemos nuestra pagina de inicio del repositorio.
Nos indica unos cuantos comandos, y uno de ellos es el que nos interesa, que es el siguiente:
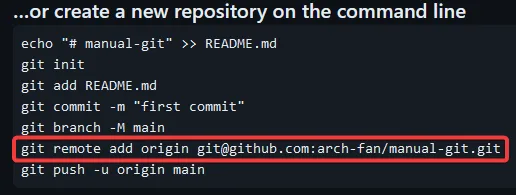
Ese comando lo copiamos y lo introducimos en nuestro terminal.
Una vez introducido, ya estará nuestro repositorio remoto conectado a nuestro repositorio local.
Básicamente, añade un origen remoto a través de SSH, que es que está indicado al final.
Flujo de trabajo
Git sigue un flujo de trabajo en sus ramas. Este consta de cuatro fases:
- Creación o modificación de un archivo
- Staging
- Commit
- Sincronización con el Repositorio Remoto
Para seguir el flujo de trabajo en el repositorio, usaremos el comando “git status”.
Creación o modificación de un archivo
Primero, empezaremos creando un fichero, en mi caso usare vim, pero puedes usar el editor de texto que quieras.
Primero, vamos a comprobar como se ve git status sin añadir ningún fichero:

Nos dice en la branch en la que estamos, que no hemos hecho ningún commit, y que no hay nada en lo que hacer commit. Entonces, vamos a crear un fichero. Lo llamaré “prueba.txt” y añadiré un poco de texto:

Aquí vemos que se ha creado el fichero. Vamos a comprobar nuestro git status
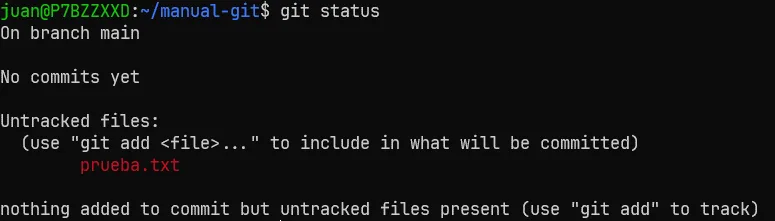
Ya nos esta diciendo que hay un fichero que esta “untracked”, porque no se ha stageado todavía, asi que vamos a ello.
Staging
Para pasar un fichero a la fase “staging”, ejecutamos el comando “git add” seguido del nombre del fichero que queramos pasar:
git add prueba.txt
Ahora, si verificamos el “git status”, vemos que ha cambiado de fase:

Ya nos está diciendo que el fichero puede ser commiteado. También, si nos hemos equivocado, podemos unstagearlo con el comando que nos indica arriba. Se vería asi:
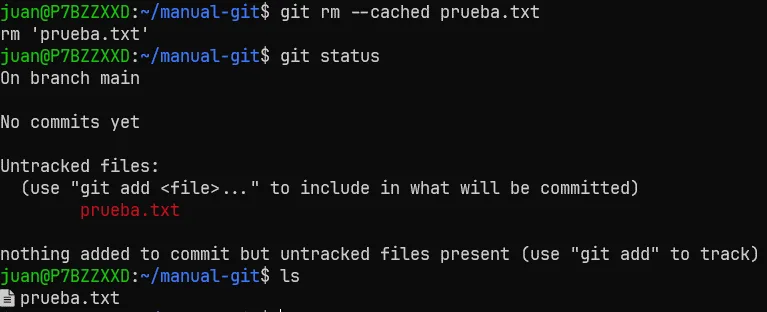
Vemos que se quita del flujo de Git, pero el fichero no desaparece.
Vamos a dejarlo añadido para pasar a la siguiente fase.
Commit
Para commitear el fichero, usaremos el comando “git commit” con el parámetro “-m” si queremos indicar un mensaje. Este mensaje se suele utilizar para indicar que cambios se han hecho, y que finalidad tiene el commit. Como es nuestro primer commit diremos “first commit, probando git”

Una vez hecho el commit, vemos que nos da una salida el comando, indicándonos la rama en la que hemos hecho el commit, el id del commit, el mensaje, la cantidad de ficheros que han sido cambiados, cuantas líneas se han insertado, y que se ha hecho con el fichero.
Si hacemos “git status” vemos que el fichero ha desaparecido, porque ya paso el commit que es la fase final del ciclo de vida, por lo que los cambios estarían hechos.

Si queremos deshacer un commit, tenemos varias posibilidades:
- git reset HEAD~1: Deshace el último commit y mantiene los cambios en la carpeta.
- git reset --soft HEAD~1: Deshace el ultimo commit y mueve los cambios a staging.
- git revert HEAD: Crea un nuevo commit que deshace los cambios del anterior commit.
Ahora mismo no utilizaremos ninguno, porque además solo tenemos un cambio y si intentamos revertir el primer commit no podremos, porque la carpeta estaría vacía.
Sincronización con el Repositorio Remoto
Si vamos ahora a nuestro repositorio remoto, no habrá nada:

Para sincronizar nuestros cambios con el repositorio remoto, usaremos el comando “git push” seguido del parámetro “-u origin main”. El parámetro lo que hace es indicarle a Git que rama tiene que seguir y en que repositorio. “Origin” hace referencia al nombre del servidor remoto y “main” hace referencia al nombre de la rama o branch.
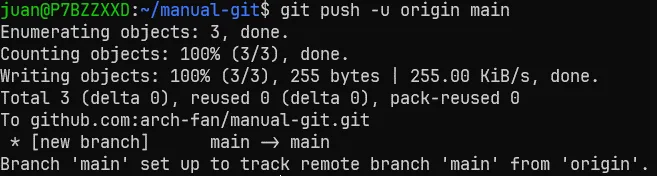
Una vez ejecutado vemos que no ha habido ningún problema, además de un poco de información extra, como el numero de bytes subidos, cual es el origen, la branch que se ha modificado, y que la branch main a sido configurada para trackear la branch remota “main” en “origin”.
Ahora, si vamos a nuestro repositorio en Github y recargamos la página, podemos ver los cambios:

Si nos fijamos, vemos que el mensaje de commit que escribimos anteriormente se ve reflejado, por lo que es muy útil ser descriptivos:
Así tendríamos una guía básica de cómo usar Git y como conectar el repositorio en remoto.